
目次
近年、AIやビッグデータの社会実装が進むにつれ、「機械学習」や「深層学習」といった専門用語を見る機会が増えています。しかし、従来の機械学習にはいくつかの弱点も見つかっており、それがネックとなり活用が進んでいない企業があることも事実です。
そこで注目を集めているのが「フェデレーテッドラーニング(連合学習)」とよばれる機械学習の手法です。フェデレーテッドラーニングは機械学習の弱点を克服できる可能性があるとして、社会実装や研究が進んでいます。
今回は、従来の機械学習とフェデレーテッドラーニングとの違いは何か、機械学習のどのような課題を解決できるのかも含めて詳しく解説します。
フェデレーテッドラーニング(連合学習)とは

フェデレーテッドラーニングとは、個人情報や機密情報といったデータを共有することなく、デバイスおよびローカル環境で解析・計算を実行し、その分析結果をクラウド上で収集・統合する手法です。
フェデレーテッドラーニングの仕組み
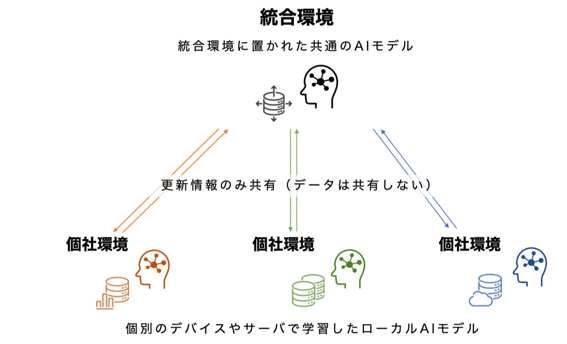
フェデレーテッドラーニングの基本的な仕組みは以下のとおりです。
- 個社のデバイスやサーバ等に共通のAIモデルをインストールする
- 個社のデバイスやサーバ等でデータを解析し、ローカルAIモデルを生成する
- 得られた解析結果やローカルAIモデルの更新情報をクラウド上の統合環境に送信する
- 統合環境でそれぞれから送られた解析結果やローカルAIモデルの更新情報をもとに共通のAIモデルを更新する
- 統合環境から個社のデバイスやサーバ等に共通のAIモデルの更新情報を共有し、アップデートを繰り返す
フェデレーテッドラーニングでは、生データを個別のデバイスやサーバ等のローカル環境で一度処理します。その後、得られた解析結果をクラウド上の統合環境へアップロードし、総合的な改善を行い共通のAIモデルを更新します。このようにフェデレーテッドラーニングは、データそのものを共有せずとも解析結果のみを中央の統合環境で学習することで、あたかもデータ連携をしたかのようにデータの利活用が可能になります。
フェデレーテッドラーニングの活用例
フェデレーテッドラーニングは、AIによる医療診断等に応用されています。たとえば、血圧等のヘルスケアデータは個人情報を含むセンシティブなデータであるため、ほかの医療機関や企業との直接的なデータ連携は難しい問題がありました。
しかし、フェデレーテッドラーニングを応用することで、患者の個人情報を含むデータは医療機関側のローカルAIモデルで解析され、解析結果のみがクラウド上へアップロードされます。
その結果、グローバルAIモデルには個人情報を含まない特徴量のみが統合されるため、直接的なデータ連携が難しい現場でもあたかもデータを連携したかのようにAIモデルを学習させ、高精度なAIモデルの構築が実現できるのです。
フェデレーテッドラーニングと機械学習の違いとは

フェデレーテッドラーニングはこれまでの機械学習と比較して何が異なるのか、フェデレーテッドラーニングを活用することでどのような課題が解決できるのかについて、解説します。
従来の機械学習の概要と課題
機械学習とは、機械(コンピュータ)が膨大なデータを学習し、一定のパターンやルールを割り出す技術のことを指します。一般的な機械学習は、データをサーバやクラウド上の1か所に集約して学習を行いますが、データを1か所に集約する必要があることから、サーバの計算処理の負荷が増大するほかデータの前処理にかかるコストも増大します。
データの「前処理」とはその名のとおり、コンピュータが計算・処理しやすいように何らかの手を加えることを指します。たとえば、データ入力の際に発生する数字以外の記号やスペース等を取り除く作業も前処理にあたります。データの前処理を行わないまま計算してしまうと誤った結果が出力されたり、精度が低下したりするケースが見られます。
また、機械学習で連携するデータには個人情報が含まれることも多く、プライバシー保護の観点から1箇所にデータを集めることは難しいといった課題もあります。このような個人情報保護法の観点からも機械学習の業務への活用が進まない一因となっています。
フェデレーテッドラーニングで改善されること
フェデレーテッドラーニングは従来の機械学習の課題である「前処理・計算コスト」を低減すると同時に、プライバシー保護を担保した状態でデータ連携を可能とする技術として期待されています。
データの連携・計算の負荷を軽減する
フェデレーテッドラーニングの仕組みでも解説したとおり、フェデレーテッドラーニングは個別のデバイスやサーバでローカルAIモデルを生成します。
従来の機械学習のように1か所にデータを集約せずに分散して処理した結果をグローバルAIモデルに集約することから、コンピュータの計算負荷を分散することが可能です。
また、1か所にデータを集約することがないため、前処理にかかる時間やコストも分散化できます。そのため、機械学習の導入にあたって費用対効果に疑問を抱いている場合でも、フェデレーテッドラーニングを応用することで計算コストの問題の改善につながると考えられます。
データのプライバシーを保ったまま計算できる
個人のプライバシー保護を保ったまま計算できることも、フェデレーテッドラーニングの特長の一つです。
膨大な量のデータを必要とする機械学習では、1箇所にデータを集めることからプライバシー保護との両立が重要な課題でした。フェデレーテッドラーニングでは生データを扱うのは個別のデバイスやサーバ側であり、クラウド上にはそれぞれの解析結果のみが集約されます。データそのものは個別のデバイスやサーバに保存されているため、個人情報はもちろん、社外に送信できない機密情報や営業情報等もフェデレーテッドラーニングで扱うことが可能です。データ連携時における情報漏えいのリスクを防ぎ、個人情報保護法をはじめとした法令、および社内規定の遵守に対応できることもフェデレーテッドラーニングならではの強みです。
まとめ
今回紹介してきたように、従来の機械学習はデータを1か所に集約したうえで解析や学習を行う手法ですが、計算負荷や前処理のコストが増大したり、プライバシー保護の担保が難しかったりといった課題がありました。
フェデレーテッドラーニングはデータ自体を共有することなく解析結果のみを統合できることから、Googleをはじめとして世界的な企業でも活用が広がっています。市場規模も2023年の1億1700万米ドルから2028年には2億100万米ドルまで拡大が見込まれており、今後さらに社会実装が進んでいくと考えられます。
EAGLYSでは、フェデレーテッドラーニングの社会実装支援のほかにもAI解析等のデータ利活用とデータのセキュリティを両立する解決方法として秘密計算サービスの提供も行っています。AI活用時のセキュリティ対策や、フェデレーテッドラーニングを用いた社内外でのセキュアなデータ利活用を検討されている方は、ぜひお気軽にお問い合わせください。